Logging¶
Compliant Kubernetes (CK8s) provides the mechanism to manage your cluster as well as the lifecycle of thousands of containerized applications deployed in the cluster. The resources managed by CK8s are expected to be highly distributed with dynamic behaviors. An instance of CK8s cluster environment involves several components with nodes that host hundreds of containers that are constantly being spun up and destroyed based on workloads.
When dealing with a large pool of containerized applications and workloads in CK8s, it is imperative to be proactive with continuous monitoring and debugging information in order to observe what is going on the cluster. These information can be seen at the container, node, or cluster level. Logging as one of the three pillars of observability is a crucial element to manage and monitor services and infrastructure. It allows you to track debugging information at different levels of granularity.
Compliance needs¶
The requirements to comply with ISO 27001 are stated in ISO 27001:2013. The annexes that mostly concerns logging are:
- Annex 12, article A.12.4.1 "Event Logging" and A.12.4.3 "Administrator and Operator Logs".
- Annex 16 which deals with incident management.
In Compliant Kubernetes, OpenSearch is separate from the production workload, hence it complies with A.12.4.2 "Protection of Log Information". The Infrastructure Provider should ensure that the clock of Kubernetes nodes is synchronized, hence complying with A.12.4.4 "Clock Synchronisation".
OpenSearch¶
Raw logs in CK8s are normalized, filtered, and processed by Fluentd and shipped to OpenSearch for storage and analysis. OpenSearch is derived from the fully open source version of Elasticsearch called Open Distro for Elasticsearch.
OpenSearch provides a powerful, easy-to-use event monitoring and alerting system, enabling you to monitor, search, visualize your data among other things. OpenSearch Dashboards is used as visualization and analysis interface for OpenSearch for all your logs.
Visualization using OpenSearch Dashboards¶
OpenSearch Dashboards is used as a data visualization and exploration tool for log time-series and aggregate analytics. It offers powerful and easy-to-use features such as histograms, line graphs, pie charts, heat maps, and built-in geospatial support.
When you log into OpenSearch Dashboards, you will start at the home page as shown below.
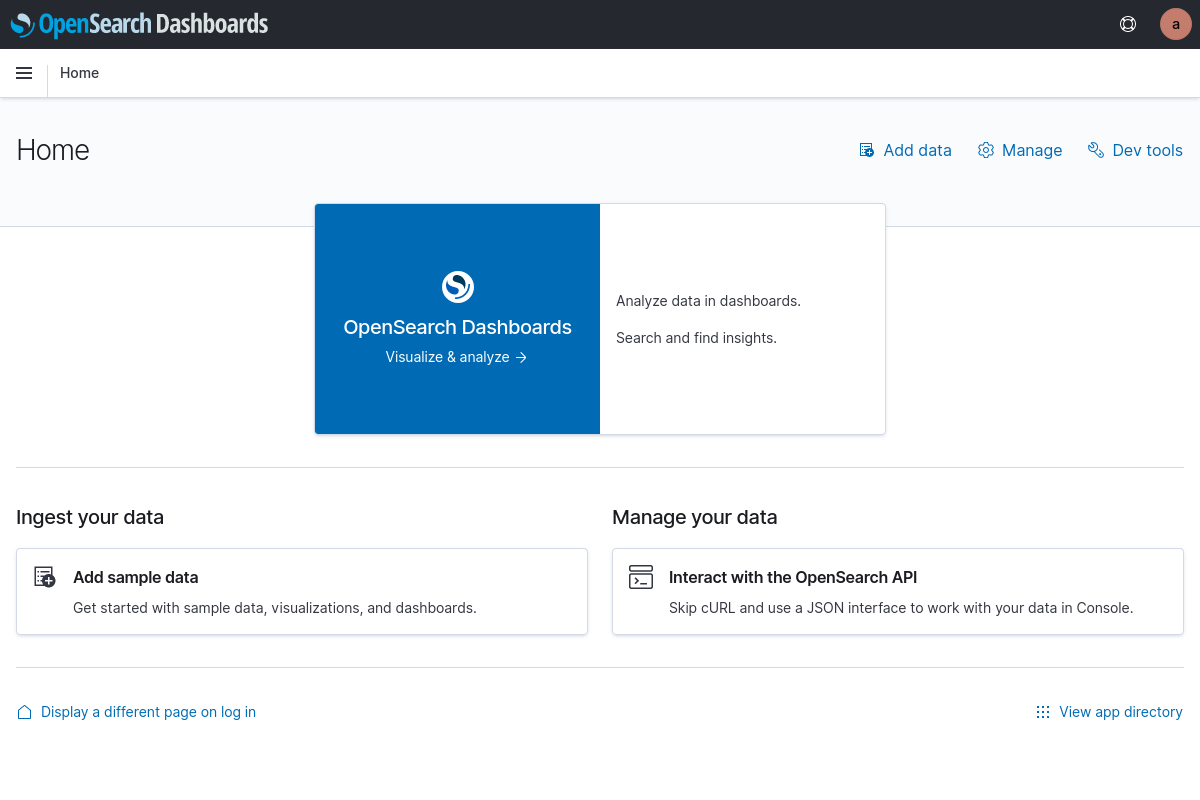
From here click "Visualize & analyze" to continue and you will be greeted with the options to go forward to either Dashboard or Discover. Opening the sidebar in the top left will also provide navigation to OpenSearch Dashboards features, and here Visualize can be found in addition to the two former two outlined in the page shown below.
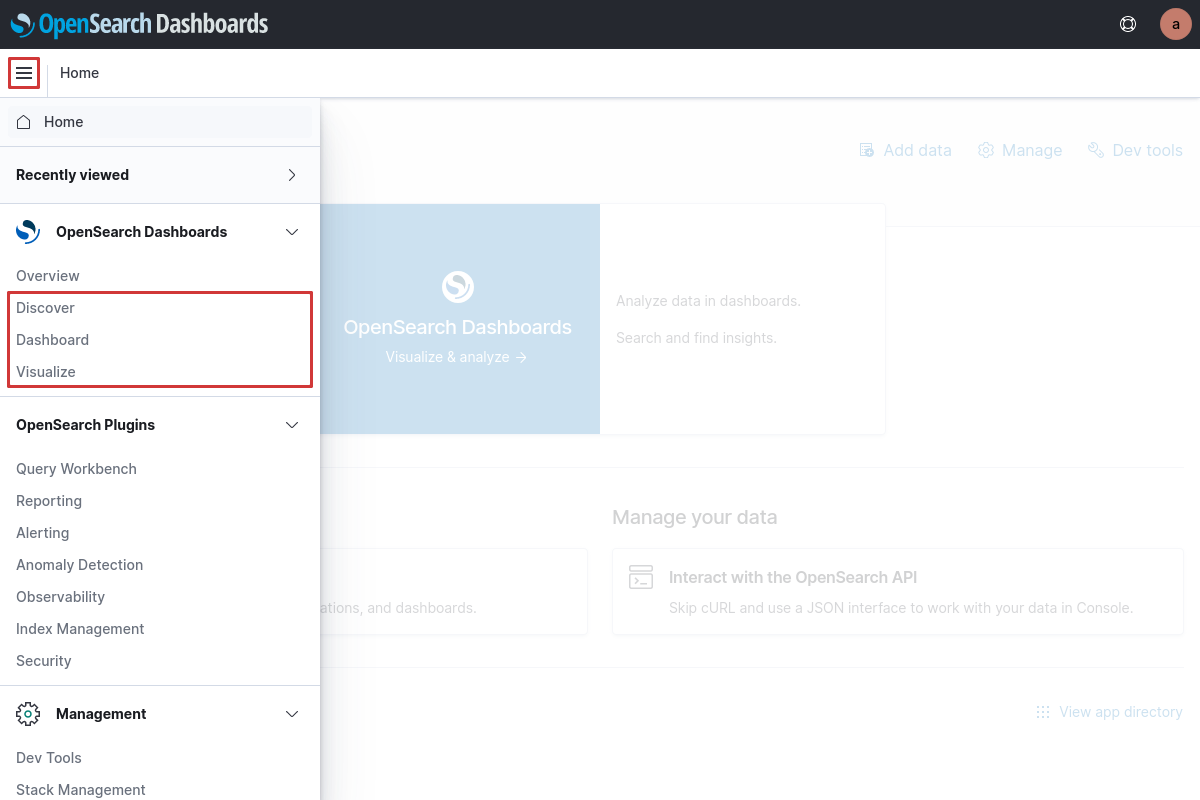
Since we are concerned with searching logs and their visualization, we will focus on these three features indicated by the red rectangle in the figure above. If you are interested to know more about the rest please visit the official OpenSearch Dashboards documentation.
Before we dive in further, let us discuss the type of logs ingested into OpenSearch. Logs in CK8s cluster are filtered and indexed by Fluentd into four categories.
Application level logs
-
Kubeaudit logs related to Kubernetes audits to provide security-relevant chronological set of records documenting the sequence of activities that have affected system by individual users, administrators or other components of the system. This is mostly related to the ISO 27001 requirement A.12.4.3 "Administrator and Operator Logs".
-
Kubernetes logs that provide insight into CK8s resources such as Nodes, Pods, Containers, Deployments and ReplicaSets. This allows you to observe the interactions between those resources and see the effects that one action has on another. Generally, logs in the CK8s ecosystem can be divided into the cluster level (logs outputted by components such as the kubelet, the API server, the scheduler) and the application level (logs generated by pods and containers). This is mostly related to the ISO 27001 requirement A.12.4.3 "Administrator and Operator Logs".
Platform level logs
-
Authlog includes information about system authorization, along with user logins and the authentication mechanism that were used. Such as SSH access to the Nodes. This is mostly related to the ISO 27001 requirement A.12.4.3 "Administrator and Operator Logs".
-
Others logs other than the above two are indexed and shipped to OpenSearch as others. These logs are collected from the Node's
journaldlogging system.
Note
Users can only view the logs of kubernetes and kubeaudit. authlog and others are for Compliant Kubernetes administrators.
Let us dive into it then.
Data Visualization and Exploration¶
As you can see in the figure above, data visualization and exploration in OpenSearch Dashboards has three components: Discover, Visualize and Dashboard. The following section describes each component using examples.
Note
These following examples were created for Open Distro for Elasticsearch and Kibana, however the user experience is the same when using OpenSearch Dashboards.
Discover¶
The Discover component in OpenSearch Dashboards is used for exploring, searching and filtering logs.
Navigate to Discover as shown previously to access the features provided by it. The figure below shows partial view of the page that you will get under Discover.
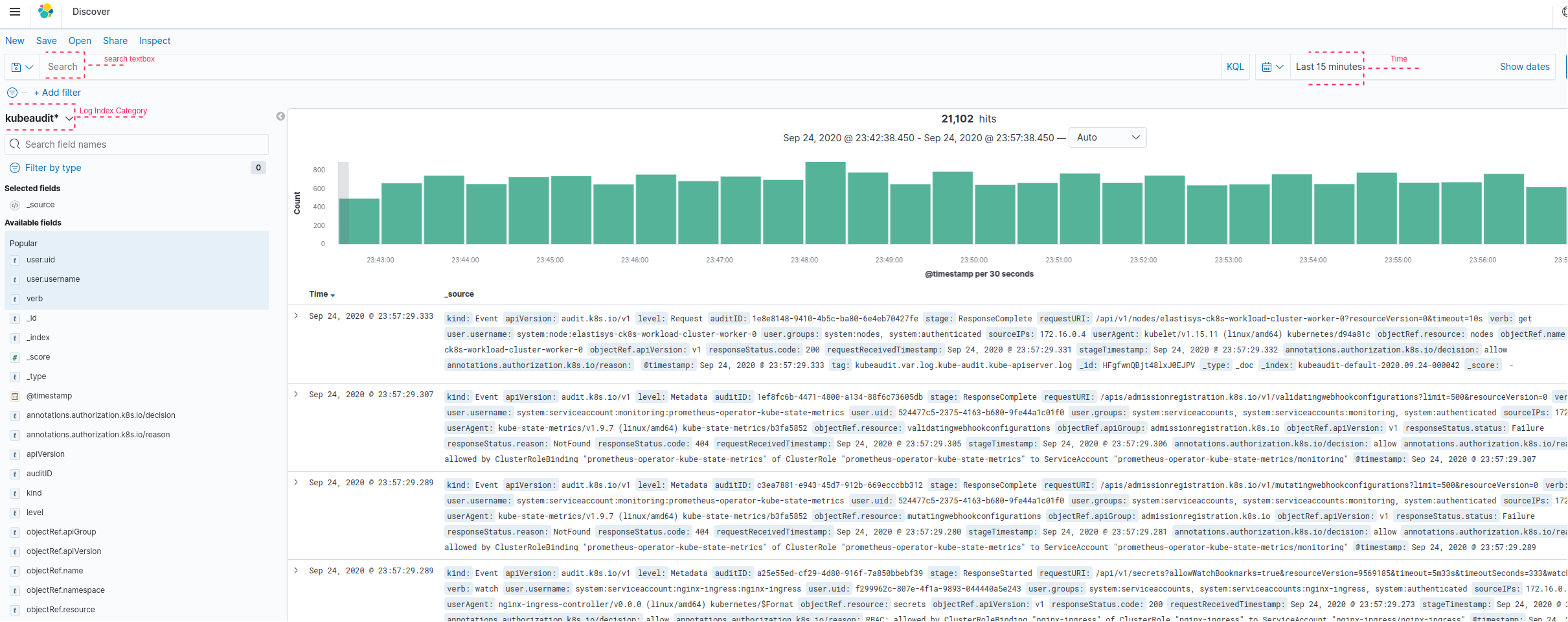
As you can see in the above figure, the kubeaudit index logs are loaded by default. If you want to explore logs from either of the other two log indices please select the right index under the dropdown menu marked log index category.
To appreciate the searching and filtering capability, let us get data for the following question:
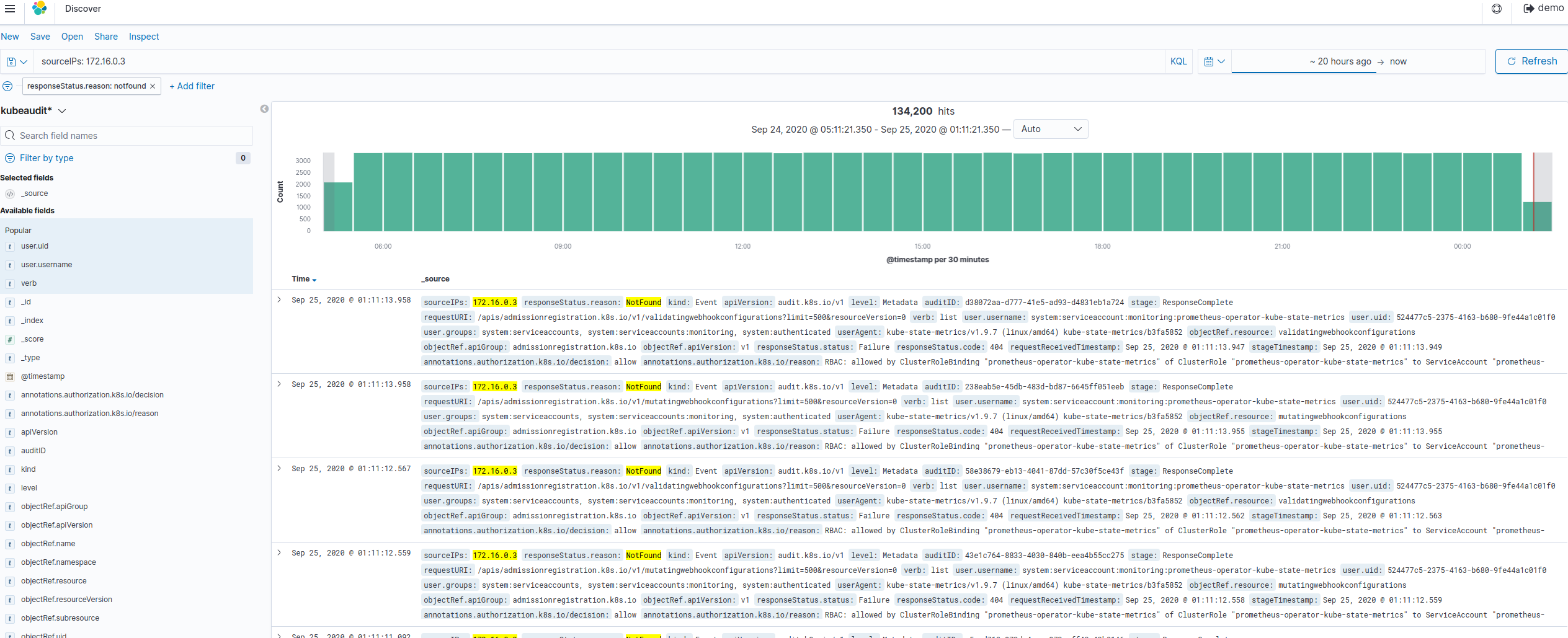
Get all logs that were collected for the past 20 hours in host 172.16.0.3 where the responseStatus reason is notfound
We can use different ways to find the answer for the question. Below is one possible solution.
-
Write sourceIPs: 172.16.0.3 in the search textbox.
-
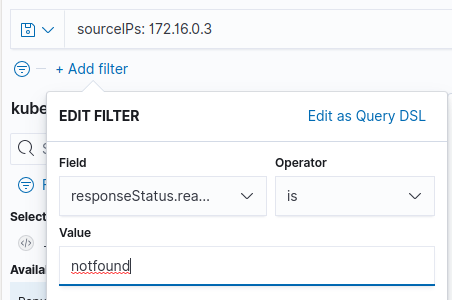
Click Add Filter and select responseStatus.reason and is under field and Operator dropdown menus respectively. Finally, enter notfound under Value input box and click Save. The following figure shows the details.
-
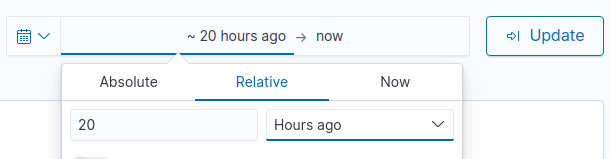
To enter the 20 hours, click part that is labelled Time in the Discover figure above, then enter 20 under the input box and select hours in the dropdown menu. Make sure that you are under Relative tab. Finally, click update. The following figure shows how to set the hours. Note that the data will be automatically updated as time passes to reflect the past 20 hours data from the current time.
Once you are done, you will see a result similar to the following figure.
Visualize¶
The Visualize component in OpenSearch Dashboards is to create different visualizations. Let us create a couple of visualizations.
To create visualizations:
- Open the sidebar and click Visualize under OpenSearch Dashboards.
- Click Create visualization button located on the top right side of the page.
- Select a visualization type, we will use Pie here.
- Choose an index pattern or saved search name under New Pie / Choose a source. You can utilize the search function. We will use the kubernetes* index here.
By default a pie chart with the total number of logs will be provided by OpenSearch Dashboards. Let us divide the pie chart based on the number of logs contributed by each namespace. To do that perform the following steps:
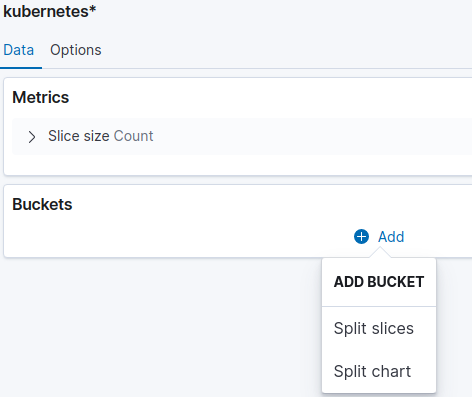
-
Under Buckets click Add then Split slices. See the figure below.
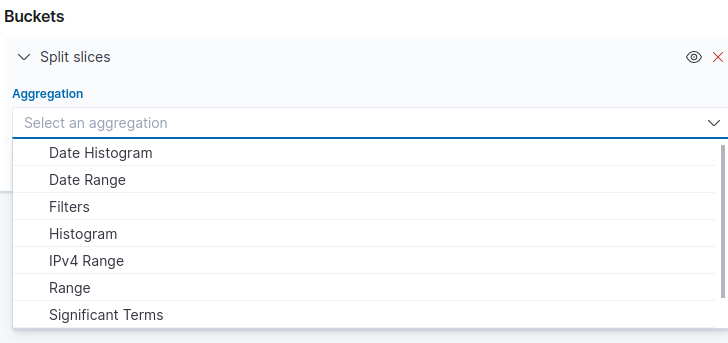
-
Under Aggregation select Significant Terms terms. See the figure below.
-
Under Field select kubernetes.namespace_name.keyword and under Size input 10. See the figure below.
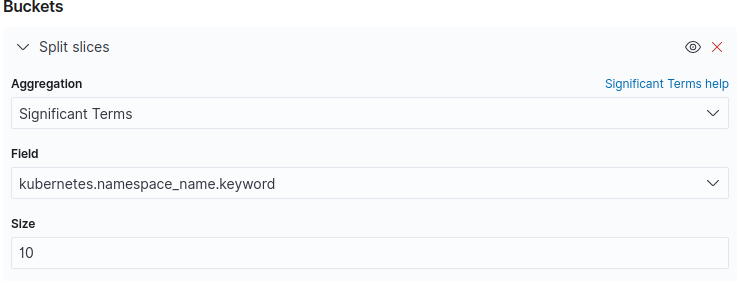
-
Click Update button located in the bottom right corner.
The final result will look like the following figure.
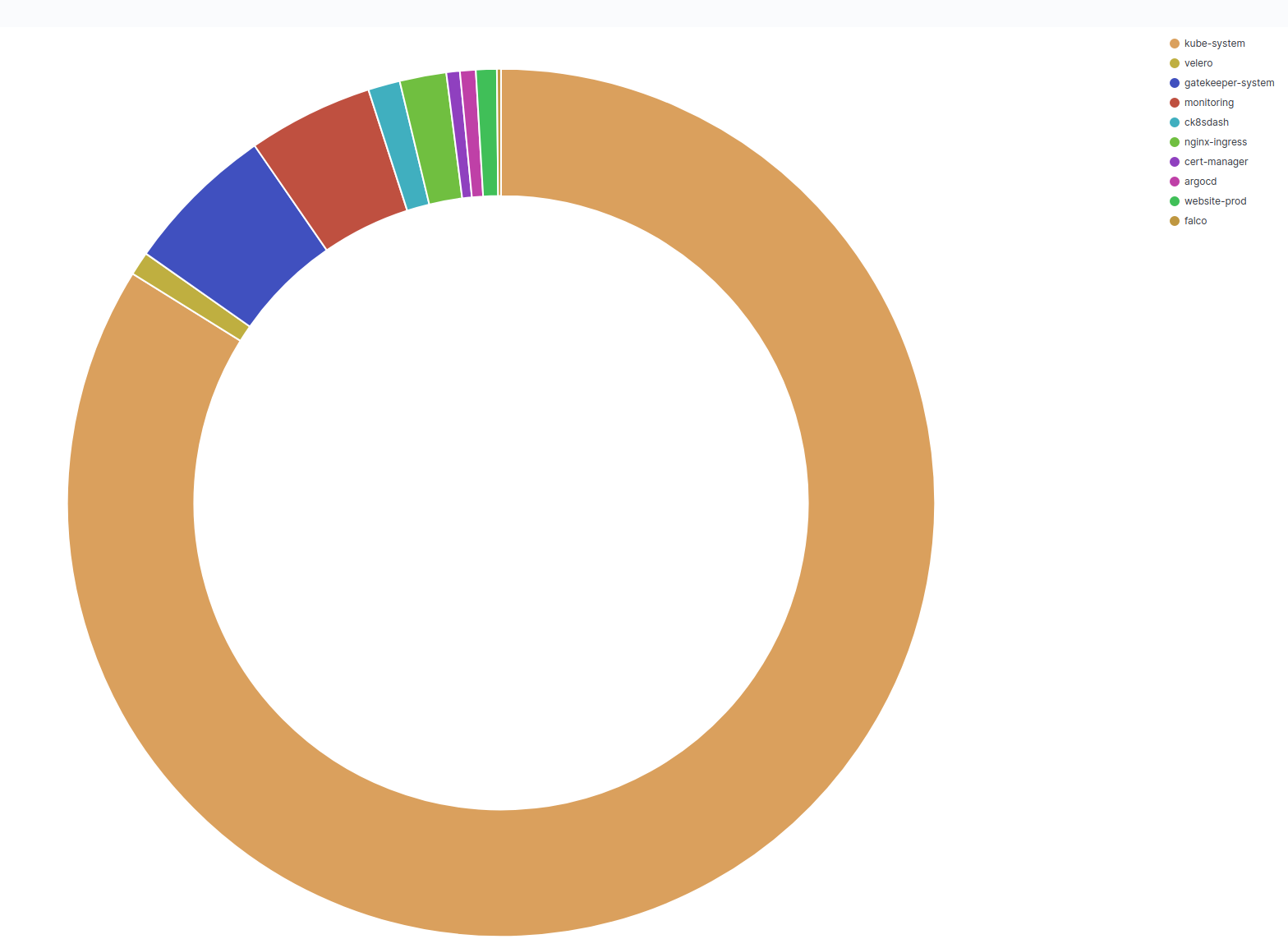
Please save the pie chart as we will use it later.
Let us create a similar pie chart using host instead of namespace. The chart will look like the following figure.
Dashboard¶
The Dashboard component in OpenSearch Dashboards is used for organizing related visualizations together.
Let us bring the two visualizations that we created above together in a single dashboard.
To do that:
- Open the sidebar and click Dashboard under OpenSearch Dashboards.
- Click Create dashboard button located on the top right side of the page.
- Click Add an existing link located on the left side.
- Select the name of the two charts/visualizations that you created above.
The figure below shows the dashboard generated from the above steps showing the two pie charts in a single page.

Accessing Falco and OPA Logs¶
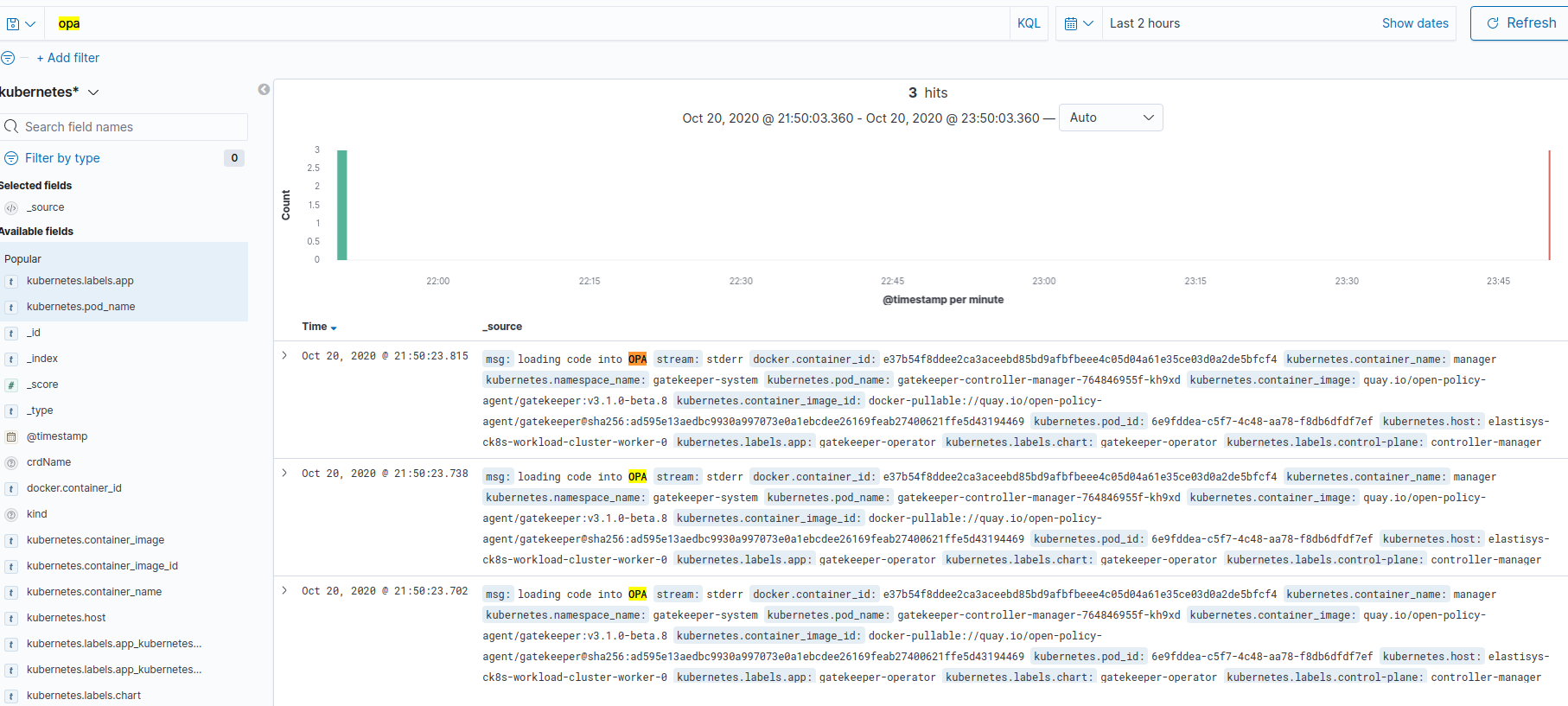
To access Falco or OPA logs, go to the Discover panel and write Falco or OPA on the search textbox. Make sure that the Kubernetes log index category is selected.
The figure below shows the search result for Falco logs.
The figure below shows the search result for OPA logs.
OpenSearch Mappings¶
An index mapping specifies the data structure of the data within that index, listing all the fields and their data types.
Mappings can be created:
- Dynamically by OpenSearch
- Explicitly on index creation
- Using Templates
For example, if you index an integer field without pre-defining the mapping, OpenSearch sets the mapping of that field as long.
Importantly, a field can only be of one type, sending data of another type can result in a mapping conflict and data being rejected.
In Compliant Kubernetes, index mappings are dynamically created from the data you send in. To set explicit mappings, reach out to your platform administrator. A mapping conflict occurs when you try to send data into a field that already has a mapping created but the data doesn't meet the same type (date, integer, string, etc.)
A very short example of index mapping is displayed and commented below:
{
"movies": { # Index name we're looking at
"mappings": {
"properties": {
"release_date": { # The release_date field is of
"type": "date" # date format allowing for time based
}, # searching, eg between 1970 and 2000
"title": { # The title field stores the title,
"type": "text", # and is of type text,
"fields": { # and also a keyword
"keyword": { # less than 256 bytes in length
"type": "keyword", # the default limit is to avoid
"ignore_above": 256 # the excessive disk/memory usage
}
}
},
}
}
}
}
To learn more, see Configuring OpenSearch Mappings.
Handling Mapping Conflicts¶
If you get the following error:
Mapping conflict! A field is defined as several types (string,
integer, etc) across the indices that match this pattern. You may still
be able to use these conflict fields in parts of Kibana, but they will
be unavailable for functions that require Kibana to know their type.
Correcting this issue will require re-indexing your data.
This means that your application has changed the type of a field in your structured logs. For example, say version A of your application logs the HTTP request path in request. Later, version B logs the HTTP request path in request.path and the HTTP verb in request.verb. Essentially, request has changed from string to dictionary.
As a first step, review your application change management policy to reduce the chance of a log field changing type.
Second, ask your administrator to re-index the affected indices.
Note
Re-indexing requires a lot of permissions, including creating and deleting indices, and changing Index templates. This may interfere with audit logs and compromise platform security. Therefore, to ensure platform security, re-indexing can only be performed by Compliant Kubernetes administrators.
Running Example¶
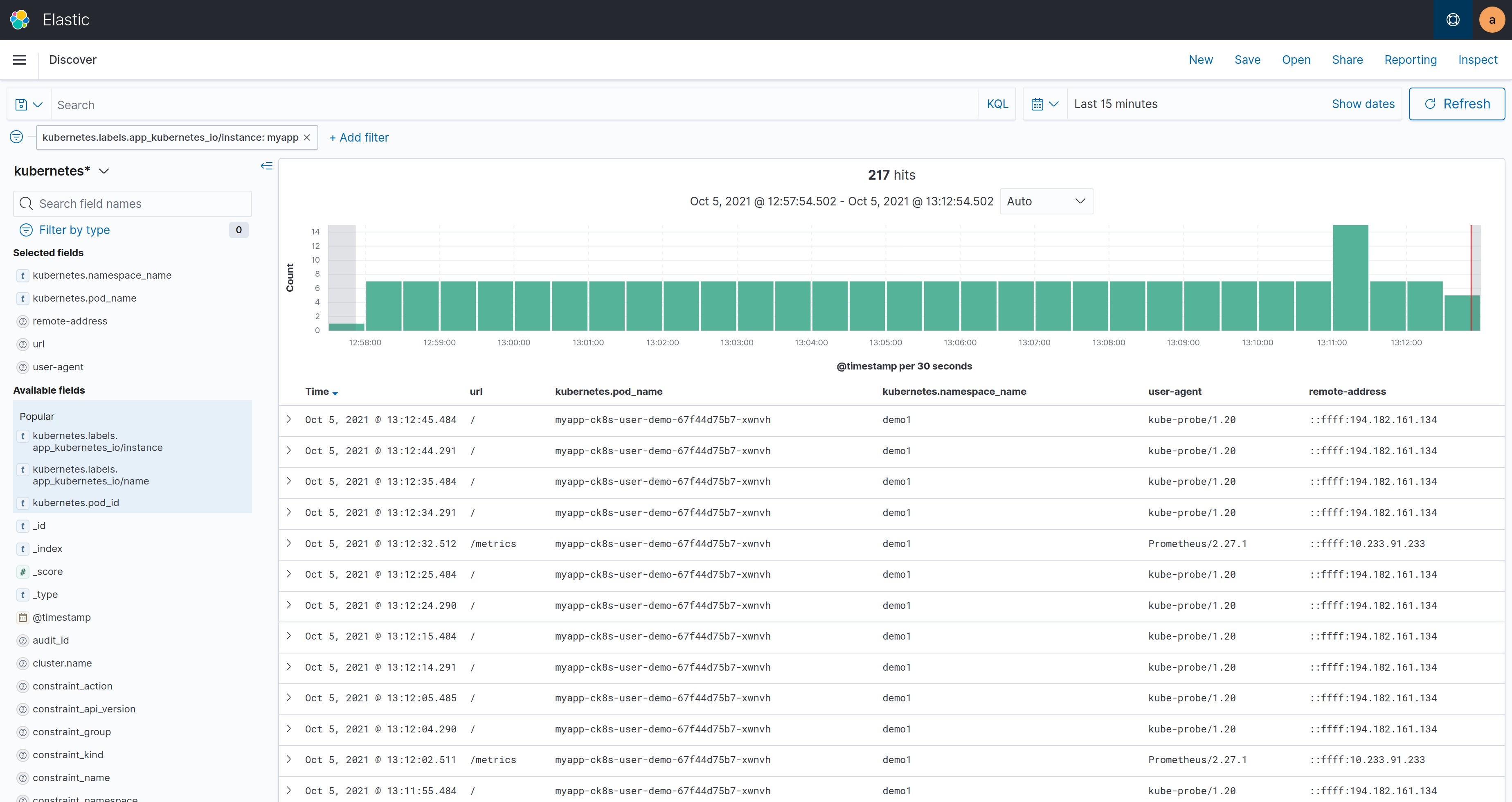
The user demo application already includes structured logging: For each HTTP request, it logs the URL, the user agent, etc. Compliant Kubernetes further adds the Pod name, Helm Chart name, Helm Release name, etc. to each log entry.
The screenshot below gives an example of log entries produced by the user demo application. It was obtained by using the index pattern kubernetes* and the filter kubernetes.labels.app_kubernetes_io/instance:myapp.
Note
You may want to save frequently used searches as dashboards. Compliant Kubernetes saves and backs these up for you.
Exporting logs¶
At the moment the reporting feature in OpenSearch doesn't work so instead we recommend you to use elasticsearch-dump.
For Elastisys Managed Services Customers
Elasticsearch-dump is not enabled by default, but can be requested by filing a service ticket.
Example of exporting the kubernetes-* index pattern to a folder opensearch-dump:
docker pull elasticdump/elasticsearch-dump
mkdir opensearch-dump
# OpenSearch username and password
# This will be handed out from your Compliant Kubernetes administrator
OPENSEARCH_USERNAME="your-username"
OPENSEARCH_PASSWORD="your-password"
# Your domain that is used for your cluster.
# This is the same as the one you are using for your other services (grafana, harbor, etc.)
DOMAIN="your-domain"
docker run --rm -ti -v $(pwd)/opensearch-dump:/tmp elasticdump/elasticsearch-dump \
--input="https://${OPENSEARCH_USERNAME}:${OPENSEARCH_PASSWORD}@opensearch.ops.${DOMAIN}/kubernetes-*" \
--type=data \
--output=/tmp/opensearch-dump.json \
--searchBody='{"query":{......}}'
For more examples and how to use the tool, read the documentation in the repo.
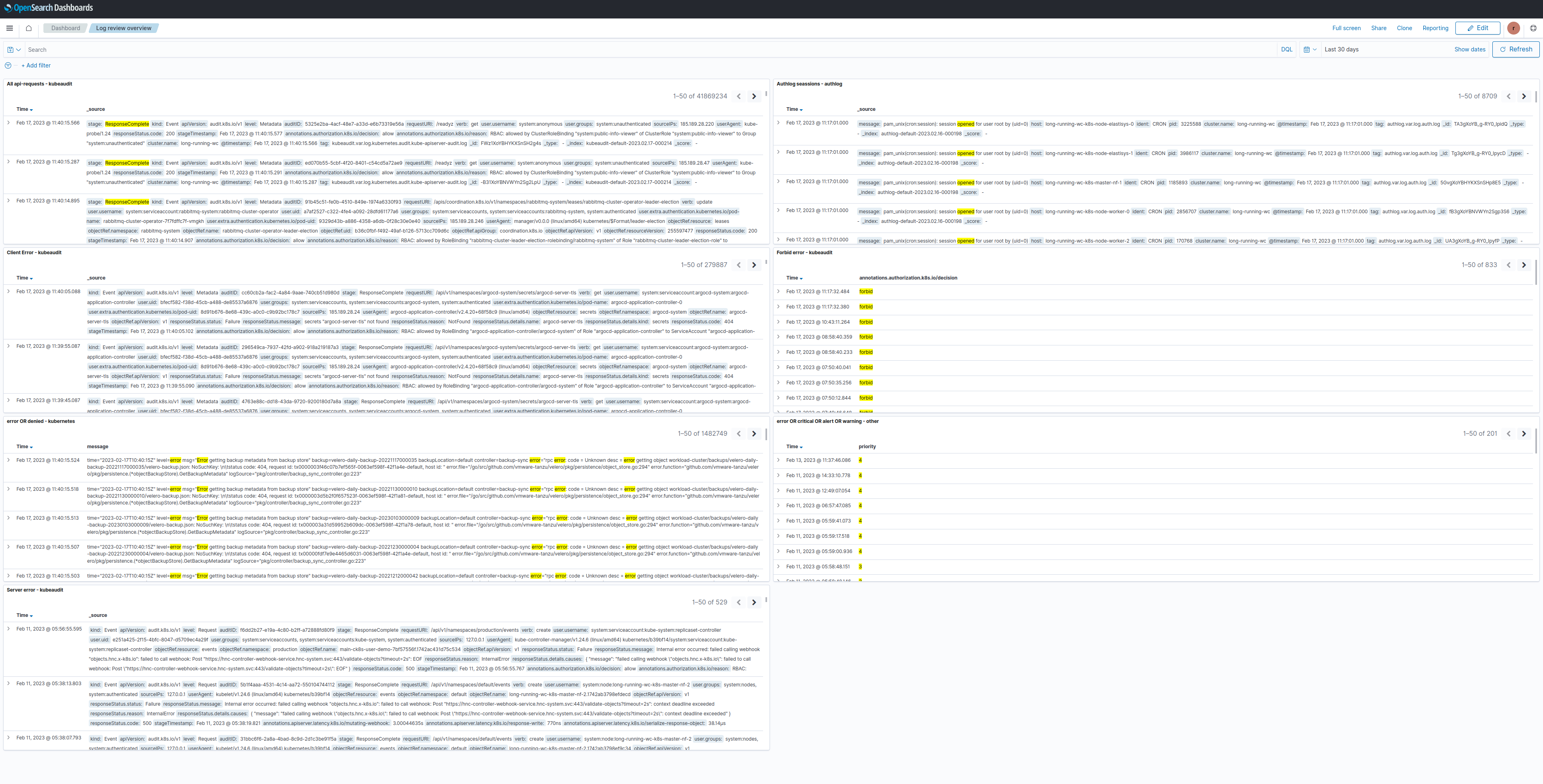
Log review dashboard¶
This dashboard can be viewed to get a quick overview of the cluster's state.
-
kubeaudit¶
- All api-requests = Successful API requests
- Forbid error = Forbidden API requests
- Client Error = Client error logs
- Server error = Server error logs
-
kubernetes¶
- error OR denied = Error & denied logs
-
other¶
- error OR critical OR alert OR warning = System logs of priority 1-4
-
authlog¶
- number of authlog sessions = Authlog sessions